
In the previous blog we saw how to get started with Apache Spark, perform basic transformations and actions. Lets get little deeper in this blog
Data Exploration Using Spark
In this blog, we will learn to:
- Exploring data
- Create temporary table
- Write SQL query
- Perform joins
How many time zones are there from Windows / Non-Windows operating system
We will be using the same dataset that we used previously. In our dataset, we have a field named “a”, which contains information about the browser, device or application. We need to identify if the data in the field “a” contains “windows” to group them based on time-zone.
Since we have registered the data as a table in Spark , let’s extract the “a” column and analyze it.
val a = sqlContext.sql(“select a from records”)
a: org.apache.spark.sql.SchemaRDD =
SchemaRDD[8] at RDD at SchemaRDD.scala:108
== Query Plan ==
== Physical Plan ==
Project [a#1]
PhysicalRDD [_heartbeat_#0,a#1,al#2,c#3,cy#4,g#5,gr#6,h#7,hc#8,hh#9,kw#10,l#11,ll#12,nk#13,r#14,t#15,tz#16,u#17], MappedRDD[5] at map at JsonRDD.scala:47
Let’s try to look at what data it contains.
a.take(5).foreach(println)
[Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11]
[GoogleMaps/RochesterNY]
[Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; InfoPath.3)]
[Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/534.52.7 (KHTML, like Gecko) Version/5.1.2 Safari/534.52.7]
[Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.79 Safari/535.11]
We need to check if each row in “a” contains the element “Windows“. If it does, then map the entire record to “Windows”, and if not, then map it to “Not Windows”. We can use map transformation to accomplish this.
map{row =>
if(row.contains(“Windows”)) “windows” else “not windows”}
We have created an inline function which takes a string as an input, “row” in our case, and then puts it into an ‘if‘ loop, and then evaluates.
Note : In Scala if/else loop has a value, namely the value of the expression that follows if or else.
Most of the times, when the data is not clean, it contains null values empty values. Let’s handle this by using exception handling in scala inside a map method.
map(row =>try{row.getString(0)} catch{case e:Exception =>“NULL”})
Note : This is just for demonstration, do not treat it as proper exception handling. We are hard-coding NULL for any kind of exception, which is not the best practice. But for demonstration alone, it serves the purpose.
Let’s chain all the above together. .
valoperating_system = sqlContext.sql(“select a from records”)
.map(x =>try{x.getString(0)} catch{case e:Exception =>“NULL”})
.map{x =>
if(x.contains(“Windows”)) “windows” else if (x.contains(“NULL”)) “NULL” else “not windows”}
To answer our initial question, we need to pair the time zone data “tz” and operating system data derived from “a” , which represents information about the browser and application.
Spark comes up with a transformation to do this. Zip pairs two RDD’s. The functionality of zip from the official spark documentation is as follows:
Zips this RDD with another one, returning key-value pairs with the first element in each RDD, second element in each RDD, etc. Assumes that the two RDDs have the *same number of partitions* and the *same number of elements in each partition* (e.g. one was made through a map on the other).
Let’s pair the time zone data ‘tz‘ and operating system data.
valpairedtzzip = tz.zip(operating_system)
pairedtzzip.take(5).foreach(println)
(America/New_York,windows)
(America/Denver,not windows)
(America/New_York,windows)
(America/Sao_Paulo,not windows)
(America/New_York,windows)
Creating a SparkSql Temporary Table
To answer our question, we need to group data by time zones and operating systems. This forms a table structure and is quite straight forward to analyze it using an SQL query.
Let’s create a temporary table to write our SQL queries on. As a first step, you need to create a case class which helps to parse and map each row of data to its corresponding fields.
In our case, we have two fields, so we will create a case class with fields named “tz” and “os” .
case class tzos(tz:String,os:String)
Lets map our data to the new class.
val pairedtzzip = tz.zip(operating_system).map(x => tzos(x._1,x._2))
Now we need to register our RDD as a temporary table.
importsqlContext._
pairedtzzip.registerTempTable(“paired”)
Note: import sqlContext._, is used to convert RDD’s with required type information into SparkSql’s specialized RDD’s for querying.
Now let’s write an sql query to group the data based on time zone with the count of operating. system.
valgroupedTz = sqlContext.sql(“select tz,count(os) as total,os from paired group by tz,os order by total desc” )
The above query gives me data in the form, where Windows and non-Window operating system count for a particular time zone are on different rows.
groupedTz.take(5).foreach(println)
[America/New_York,912,windows]
[America/New_York,339,not windows]
[America/Chicago,285,windows]
[,276,windows]
[America/Los_Angeles,252,windows]
But we need it to be in the same row.
To convert the data into the form, let’s create two different RDD’s, one with all time zones for windows, and another for non–Windows.
valwindows = groupedTz.map(x => (x.getString(0),x.getLong(1),x.getString(2))).filter(x => x._3 == “windows” ).map(x => (x._1,x._2))
valnotwindows = groupedTz.map(x => (x.getString(0),x.getLong(1),x.getString(2))).filter(x => x._3 == “not windows”).map(x => (x._1,x._2))
Performing Joins
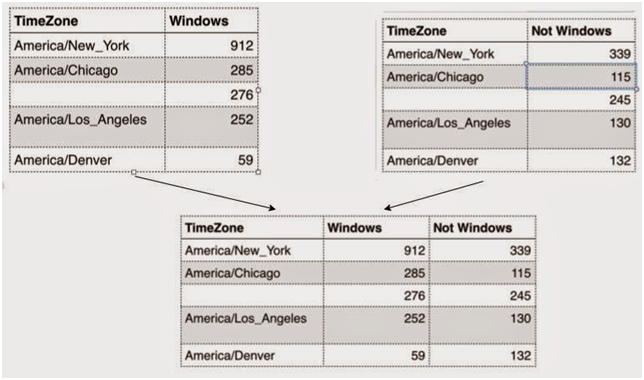
We are almost there. Now we have two key/value pair RDD with same key. Spark provides join,leftOuterJoin , rightOuterJoin and fullOuterJoin.
windows.fullOuterJoin(notwindows).take(5).foreach(println)
(Europe/London,(Some(31),Some(43)))
(Asia/Jerusalem,(Some(1),Some(2)))
(,(Some(276),Some(245)))
(America/St_Kitts,(None,Some(1)))
(Europe/Uzhgorod,(Some(1),None))
If you have come till here, , try the following:
- Perform a leftOuterJoin and rightOuterJoin and examine the output
- Try to create a new case class and register our processed data with timezone,windowcount,nonwindowcount as fields.
In the next blog, we will be looking intoCaching, Lazy Evaluation and Optimization techniques.

Vishnu is a former Happiest Mind and this content was created and published during his tenure.



