
Observability plays an important role in distributed systems. Several data types constitute observability. Also, collecting, storing, and analyzing data from a distributed system can pose challenges.
Let’s begin with understanding its need, some of the maturity models, implementing design patterns, and its overall benefits for distributed applications.
We define observability as the ability to answer any question about your distributed applications, at any time, no matter how complex the infrastructure. By instrumenting systems and applications to collect metrics, traces, and logs and sending this data to a system, one can store and analyze it to gain insights.
Among the major challenges that organizations face is observing & monitoring distributed systems. The success of organizations heavily depends on the availability and performance of their client applications. With DevOps and microservice architectural styles, applications are decoupled into services with complex interactions and dependencies. Although these paradigms enable individual development cycles with reduced delivery times, they cause several challenges in managing the services in distributed systems.
To start the implementation of observability for distributed applications, organizations need to assess the current maturity level in Implementing Observability and focus on increasing the maturity levels.
Below are the maturity levels, based on the level of insights that can be generated by consuming Logs, Traces, and Metrics:
- Level 1 – Consuming event and component level metrics and generating alerts.
- Level 2 – Consuming event and component level metrics, metrics logs, and traces and generating a comprehensive dashboard.
- Level 3 – Consuming event and component level metrics, metrics logs and traces, time series topology and generating comprehensive Dashboard, automated Root cause analysis, and understanding cause and effect of change.
- Level 4 – Proactively enable observability by bringing predictive and preventive insights using AIML Models.
Implementing Design Patterns for Observability
The first step towards implementing observability is to design distributed applications using observability patterns, as indicated below:
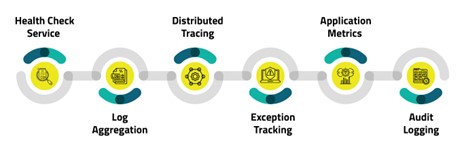
Appended is the comprehensive dashboard generated by designing patterns of observability in microservices-based applications indicating the metrics across six design patterns of observability.
- Health Check Service: Monitor microservices by identifying the service which is not running due to loss of connection with DB, monitor resource availability for microservices and dependencies.
- Create a centralized log service that consolidates logs from every service. Developers can search and analyze log files, set alerts if the predefined message appears in logs, and identify events that have disrupted the production environment.
- Track microservice, which gives Slow API response by implementing Distributed Tracing. Distributed tracing tracks request through each module service and provides end-to-end visibility, as illustrated in the diagram below.
- Exception Tracking: Implement a centralized service that generates alerts and does exception management; this helps in early problem detection to developers for rectification.
- Application Metrics: Gather metrics that provide critical information about an application’s health from all parts of its technology stack, from infrastructure-level metrics such as CPU, memory, and disk utilization to application-level metrics such as service request latency and the number of requests processed.
- Audit Logging: Each service should create an audit log entry in the database. Sequential record of user activity within the organization to ensure compliance with relevant industry regulations and your organization’s business policies.
Designing Microservices Application for Observability will help answer several questions like the time taken for the request to traverse each microservice, the sequence of calls made during a user request, steps taken by each microservice to complete a request, deviation from the normal behavior of the system, the consolidated metrics and log view for all services.
Below are a few benefits of Observability in Distributed Applications:
- Comprehensive understanding of complex distributed systems: Distributed systems are considerably more complex than monolithic computing environments and raise challenges around design, operations, and maintenance, for example, Increased opportunity for failure.
- Faster problem-solving and shorter MTTR: By monitoring the performance of the microservices using comprehensive dashboards, developers can identify any potential problems and work on remediation.
- More insightful incident reviews: Any issues can be traced back to the root cause much faster due to comprehensive insights into the performance of microservices.
- Better uptime and performance: By implementing the 6 design patterns we discussed, we get a comprehensive overview of the health of the services, enabling better performance and uptime.
- Happier customers and more revenue: Implementation of Design patterns for distributed applications will enable us to identify problems in advance, preventing downtime and revenue loss.
Observability is a vital concern for distributed systems. While it is still complex and tedious to assemble, observability is fast growing with the development of new, innovative solutions in the market. Observability in distributed applications helps companies drive operating efficiency, innovation, and growth. Designing distributed applications for observability would allow us to measure the system’s internal state through external outputs. It will enable teams to be aware of what’s occurring throughout their environments, identify and fix issues to ensure that systems are reliable and efficient, and drive customer satisfaction.

serves a dual role at Happiest Minds as the Location Head for Pune and as the Microsoft Practice Director for Product & Digital Engineering Services. With extensive experience in modernization and emerging technologies, he is passionate about driving growth in his location and enhancing his team’s capabilities to tackle customer challenges. With over 25 years of experience in leading IT services companies, Kiran Chandran R holds a diploma in advanced computing from CDAC and a B.E. in Electronics and Communications.


