With the increased adoption of big data in the past few years, the Hadoop ecosystem has exploded with many new projects. Now, coupled with the emergence of support from major vendors for enterprise connectors and security improvements Hadoop has become even more attractive to enterprise level businesses. With more information being gathered than ever before, it’s no wonder why Hadoop has become a compelling option for any business and hard to ignore by vendors in the big data processing space.
I often come across customers and technical people with specific issues. Most are unsure if their problem can be addressed through Hadoop. Because many of my encounters involve those with DWH (data warehousing) backgrounds, I think it’s time I talk about this topic specifically.
I believe we are on the brink of a huge transformation in the data warehousing space. We’re used to the EDWs (Enterprise Data-warehouse) on RDBMS (Relational Database Management Systems). In recent years, data volumes have increased exponentially, and now varies is ways never seen before making data-warehousing quite challenging, time consuming, and often times expensive. With all due respect to RDBMSs, they cannot readily address and accommodate these ever-growing data types, and formats, let alone the sheer volume of incoming data. Over the past decade, appliances such as Netezza, Teradata, etc., have evolved to address the challenge of managing large data volumes. Unfortunately these appliances are prohibitively expensive to set up. This monstrous cost appears not only at implementation, but several times later during upgrades. It might all be worth it, if it were not for the fact that these appliances aren’t very flexible in handling raw data.
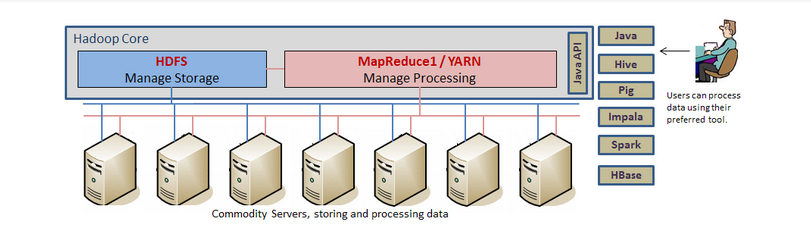
Hadoop is a fitting answer to these challenges. To put it simply, Hadoop is a distributed storage and parallel processing engine which can run on a cluster of commodity servers; making it highly scalable and fault tolerant. Hadoop stores data on its distributed file system (called HDFS) which supports very high I/O throughput. The data processing (done by other components such as MapReduce, HBase, Impala, etc.) takes advantage of data locality, effectively reducing the network I/O overhead. With recent architectural improvements (like YARN) and various other ecosystem projects, you will be able to access and process warehoused data in a variety of ways. The available storage and processing abilities scale almost linearly with the number of machines and the flexibility to access and process data making Hadoop the ideal choice for Big Data processing.
At its heart, Hadoop is a data storage and analysis (process) engine for huge volumes of data, originally built to process web pages from all over the internet. A mammoth task even then, today Google processes over 25 petabytes of data every day to keep their search up to date. To do this, Google implements data processing and algorithms to compute simple stats such as: word count, N-grams, page ranking, indexing, etc. With this type of functionality it’s no wonder that Hadoop is extendable to EDW, BI, and analytics as businesses see their data grow.
Historically, Hadoop only supported the data producing method used in MapReduce through Java APIs. This method proved rudimentary for data processing and required lots of development effort. The Java APIs needed implementation for every trivial function including: filter, search, join, etc. causing much frustration for developers and users alike. Later, additions such as Hive, Pig, Impala, and more have introduced new languages (SQL and Pig Latin) and simplified the Hadoop development process. In fact, it’s these tools that opened Hadoop to the world of Data-Warehousing.
A recent architectural change to the processing engine (YARN) enables data to be accessed and processed in many other ways beyond those in MapReduce. Some additions, such as “Spark” can support different workloads (batch), stream data processing in real time, and deliver near real-time responses using in-memory processing.
A key difference between traditional data warehousing and this new version of Hadoop is that Hadoop is designed to run on multiple machines in order to handle massive quantities of information. Typical warehousing would be implemented in a single relational database that serves as the central store, capable of housing significantly less data.
Let’s get deeper into how Hadoop can be used specifically for data warehousing:
If you look at a Data-warehouse, it’s merely a collection of data (ETL) from various enterprise sources. This data is rationalized, enriched (Meta data), modeled (dimensional etc.), and exposed for querying by the MIS/Business intelligence tools. You can draw parallels in Hadoop for all these layers. Raw data can be brought through Sqoop or Flume (ETL) to store in HDFS, Metadata can be managed by tools like HCatalog, data can be queried through Hive, Pig and Impala. Open source BI tools such as Pentaho and Jaspersoft can interface SQL compatible layers such as Hive and Impala with minimal changes. The combination of HCatalog and query layers (Hive, Impala, pig) makes it possible to query on raw files. The striking and amazing thing about DWH on Hadoop is that unlike in a traditional data-warehouse the same data can be processed by any other tool or by any other means keeping open numerous ways of exploring data unrestricted by a specific product or tool.
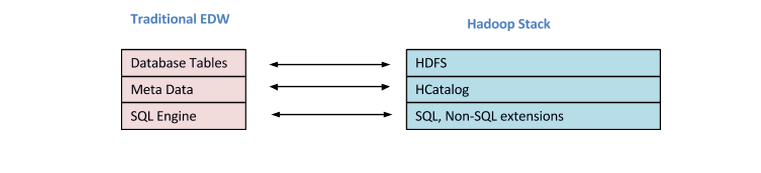
Hive and Pig use the batch-oriented MapReduce processing, while Impala relies on its own in-memory querying engine. So for near real-time responses Impala is more suitable. Of course, processing raw data can mean lower performance when compared to highly indexed and organized RDBMS. As an option, data can be further pre-processed and stored in high-performance and structured file formats such as Parquet. You can apply some of the best practices of data warehousing at this stage.

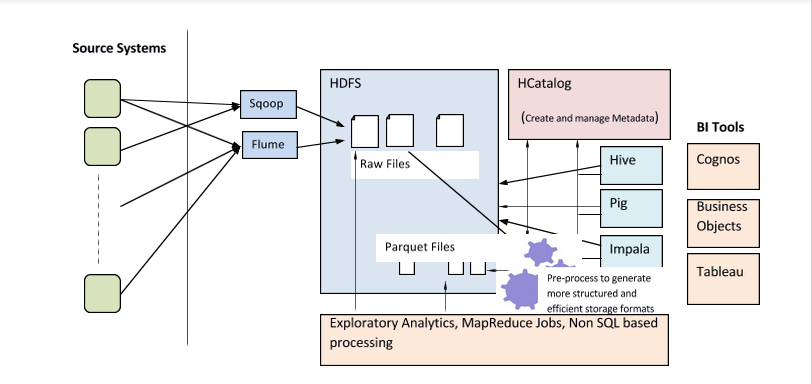

- Data can be extracted from the operational systems and external sources through Sqoop, Flume or any ETL tool supporting Hadoop. There is no need for transformations in this process. Data is typically stored in HDFS as raw files. This process can also be leveraged to create metadata.
- Optionally, metadata can be created and enriched at a later stage. The metadata can be managed through HCatalog.
- The data in HDFS can be further processed to consolidate, optimize, and enrich the information, and can then be stored in a high-performance columnar file format such as Parquet.
- This data can then be queried through tools such as Hive, Impala (SQL), Spark and Pig (Pig Latin).
- BI tools can leverage the SQL interface provided by Hive or Impala to perform analytics.
- Any ad-hoc jobs can be run or exploratory analytics can be done directly on the raw files or other files on HDFS using pig or spark.
While reading the blog, many questions may arise like, “what will happen to my existing data warehouse and the investments I’ve made?” or “What is the future of data warehousing?”
Without this becoming a “Hadoop vs. data warehousing” debate, it can be put simply: as developers, we need to see the concepts and techniques of data warehousing separately from the products and tools that enable them. Data warehousing is a crucial element for businesses and will continue to support businesses in decision making for the foreseeable future. Focus should be on obtaining and maintaining data in the best way possible in order to help businesses grow and reach their full potential.
Best practices can still be applied on Hadoop DWH without reinventing the wheel; however, data warehousing on Hadoop is still evolving. Because of the constant changes, it should come as no surprise that you will find certain processes better and easier on the traditional DWH platform. That being said, you can continue to use data warehouses for demanding tasks, and offload simpler tasks to Hadoop; freeing up precious resources for business-critical processes. Eventually, when the capacities of current data warehouses are exceeded, they may need to be migrated to Hadoop based warehouses. Organizations might also adopt hybrid approaches in conjunction with Hadoop. In any case I am so excited and keen to watch this space develop in the time to come.

Balaji has spent over 18 years in the IT Services Industry. With an experience encompassing Services and Product Marketing, he has successfully managed globally distributed Marketing and Product teams. He’s an analytical marketer with strong understanding and experience across marketing strategy, demand generation, field marketing, technology partner marketing, account based marketing, digital marketing, event management, analysis and third party relationship, PR/Media, people management, etc.