
Intelligent systems are those which can change their behavior with data. Capturing data itself is a challenge in the new age systems with IOT applications, Web Scale applications, Telematics, etc.., due to high velocity and volume of inflow and outflow of data.
For example, let’s consider an automobile insurance company, who would like to understand the user’s driving patterns, about driving habits and provide a customized premium to increase their revenue. A telematics device would have to be fitted to automobiles, regularly transmitting information about time, location , speed , braking and mileage. All these information has to be captured on the fly to generate insights like driving habits to the driver.
As this insurance model become popular, a robust number of customers would like to opt for the PAYD (Pay As You Drive) scheme. As more number of telematics devices start transmitting the driving details, the company would start to face a challenge to capture the data using traditional log storing mechanisms .
In the current system, all the telematics devices update the data to a central server, which in turn updates to a database. The current system does not scale to the new needs and process the data by multiple applications.
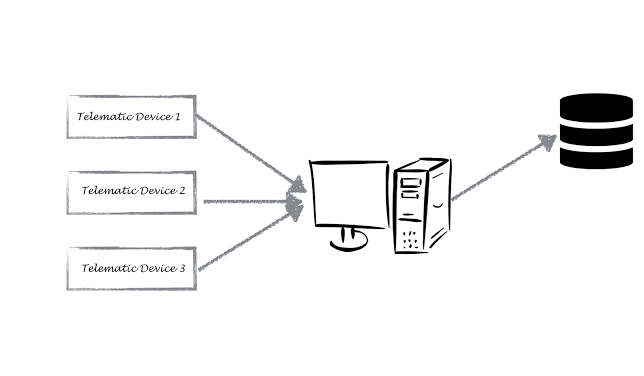
To address this problem, we need a system which is scalable, durable, have low latency and is flexible. Apache Kafka is a system built exactly for this purpose. It is a distributed log-processing platform that deals with high volumes of data at low latency.
Apache Kafka
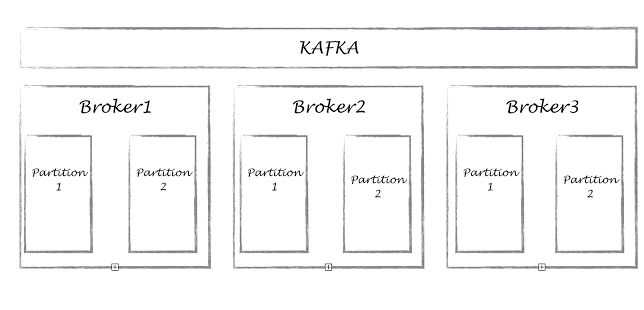
Apache Kafka is a distributed cluster of brokers. A cluster can have several topics. Topics can be considered as tables/directories, basically used to group all related information. Each topic contains multiple partitions. Each partition should fit into one broker, a topic can have several partitions. Producers (telematics devices) can write to their respective topics. Producers, in turn, can write to multiple partitions, thus balancing the workload. Consumers can eventually consume data by subscribing to topics. Consumers belonging to various consumer groups can subscribe to each topic. This helps various teams inside organization to utilize the data more meaningfully.
Let’s get our hands dirty by setting up a Kafka cluster, and by producing and consuming data from it. Download the latest version of Kafka.
Unzip the download to a suitable location. From inside the Kafka directory, let’s start a zookeeper instance and a Kafka broker.
./bin/zookeeper-server-start.sh config/zookeeper.properties
./bin/kafka-server-start.sh config/server.properties
Let’s create a topic named telematics with one partition and one replication factor.
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic telematics
We have created a Kafka topic, now let’s write into the topic. Let’s create a python-Kafka producer which will write driving information. Note that, in actual scenario it could be a telematics or any IOT device.
Kafka-python module provides low-level producer support and high level consumer and producer classes. Documentation can be found here.
It is easy to install the module if you already have a python module. Use pip to install.
sudo pip install kafka-python
Let’s create a simple kafka-python producer: .
fromkafkaimport KafkaClient,SimpleProducer
kafkaClient = KafkaClient(“localhost:9092”)
kafkaProducer = SimpleProducer(kafkaClient)
kafkaProducer.send_messages(“telematics”,“ID-203217 80 5-15-2015 00:08:13 -73.978165,40.757977”)
kafkaProducer.send_messages(“telematics”,“ID-203216 60 5-15-2015 00:08:13 -74.006683,40.731781”)
1) Import the relevant modules/library
2) Create a Kafka client instance pointing to the Kafka instance
3) Create a producer to publish message .
4) Use the producer to publish telematics information to the topic named “telematics”.
When you send a message to Kafka Queue, you get the below response:
[ProduceResponse(topic=’telematics’, partition=1, error=0, offset=3)]
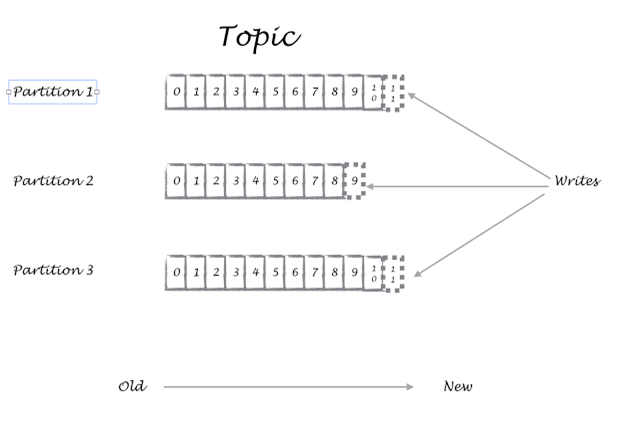
In the above response that we receive, telematics is the topic, around which, we wrote messages. Partition denotes which partition we wrote, and offset denotes the location in the partition. A single topic could contain several partitions, but a partition should fit in one machine. Partitions are replicated across the cluster for redundancy, and any copy could serve read and write requests. The cluster keeps all messages for a configured amount of time and it discards it.
Let’s write a simple Kafka python consumer to consume the data.
fromkafkaimport KafkaClient,SimpleConsumer
kafkaClient = KafkaClient(“localhost:9092”)
kafkaConsumer = SimpleConsumer(kafkaClient,“analytics”,“telematics”)
formessages in kafkaConsumer:
printmessages
Analytics is the consumer group which Kafka uses to identify when different consumers connect to a topic.
While a simple Python consumer is enough for simple purpose, we need a system which is scalable and reliable to consume the data in real-time. A few of the popular streaming application which can be used with Kafka are
Spark Streaming: Fits most of the cases, where your latency is more than a few milliseconds. One of the major advantage of Spark is its ability to reuse functionalities built for batch, a Sql interface and an easy integration with machine learning algorithm.
Storm: It is more matured than its peers, but storm implementation is not as simple as apache spark.
Samza: Samza processes messages as they are received, while Spark streaming treats streaming as a series of deterministic batch operations. Samza is still young, but has just released version 0.7.0 and is heavily used in LinkedIn.

Vishnu is a former Happiest Mind and this content was created and published during his tenure.




